
Columnar Database
Columnar databases are like relational databases in that they organize data into columns and rows. Unlike relational databases, columnar databases are completely denormalized, dividing data into groups known as column families. Column families contain data that would normally be separated into a set of columns if the data was stored in a relational database. However, unlike in a relational database, rows in a column family do not have to share a common schema. One entry can have several columns, while another might only have one or two.
Column families that are a part of the same entity share a common row key. This key is considered the primary key and is used to physically store data in order. Applications can perform lookups using a specific row key or a range of keys. Secondary indexes can also be applied to allow applications to filter by column values.
Figure 3.3 illustrates an example of a columnar database used by a company that sells bicycles and bicycle accessories. This database has two column families, one with product information and another listing quantity information. Related column families are bound by a common product key.
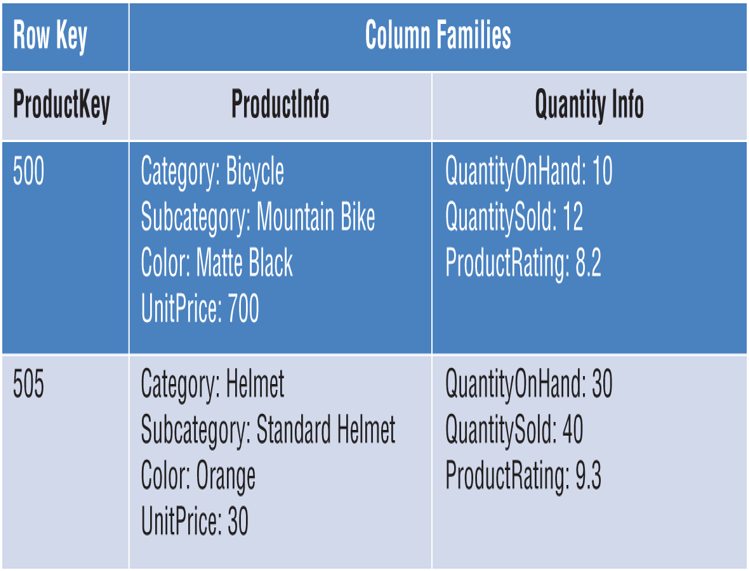
FIGURE 3.3 Columnar database
Columnar databases are typically used in analytics scenarios. Grouping data into column families allows queries to jump directly to where specific pieces of data are located. This can result in very fast aggregations since the query does not need to jump from row to row to find the field that is a part of the aggregation. Columns in a column family are also of the same data type, resulting in better data compression and faster queries.
While columnar databases are optimal for analytical workloads that aggregate data, they are not well-suited for transactional workloads where queries perform value-specific lookups. This is where a traditional relational database that stores data in a row-wise format is more performant. Writing data to a columnar database can also take more time than in a row-wise database. While new entries in a row-wise database can be inserted in one operation, columnar databases write new entries to each column one by one.
Azure provides a couple of different options for implementing a columnar database:
- Azure Cosmos DB Cassandra API
- HBase in Azure HDInsight
This chapter will focus on the Azure Cosmos DB Cassandra API. You can find more information at https://docs.microsoft.com/en-us/azure/hdinsight/hbase/apache-hbase-overview if you would like to learn more about HBase in Azure HDInsight.